Data analysis from PDFs using Camelot
Camelot was making a lots of news on Hacker News and the github repo was on of most starred too!
Pretty exicting particular given that the guys behind it are from India (home country bias! :-) )
I decided to give a try now!
First, need to get hold of a pdf using a filetype:pdf nseindia.com - Google Search.
The first result looks pretty good to try out!
I fired up Spyder from Anaconda in my virtual env.
conda activate ibPy
conda install -c camelot-dev camelot-py
spyder
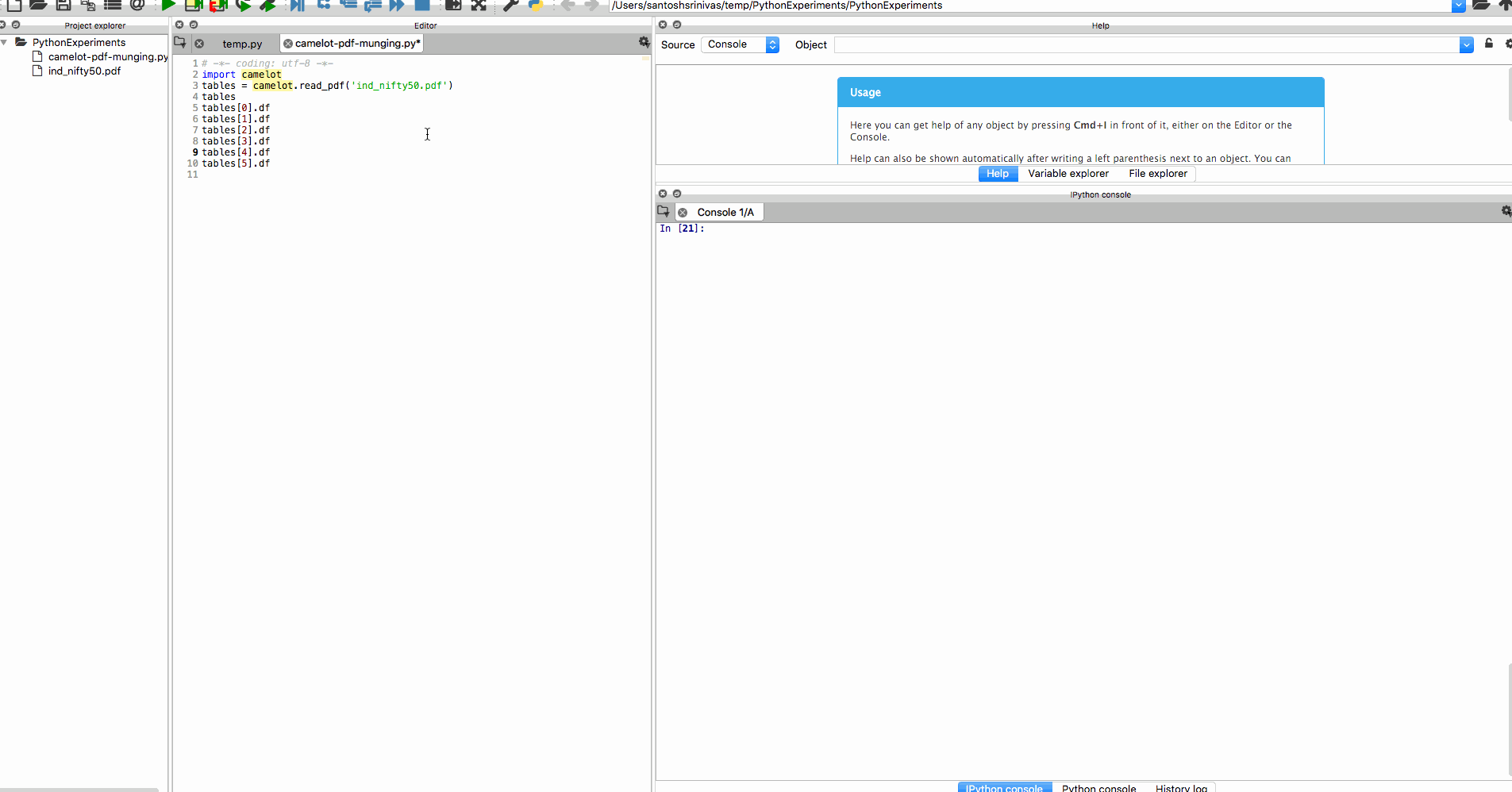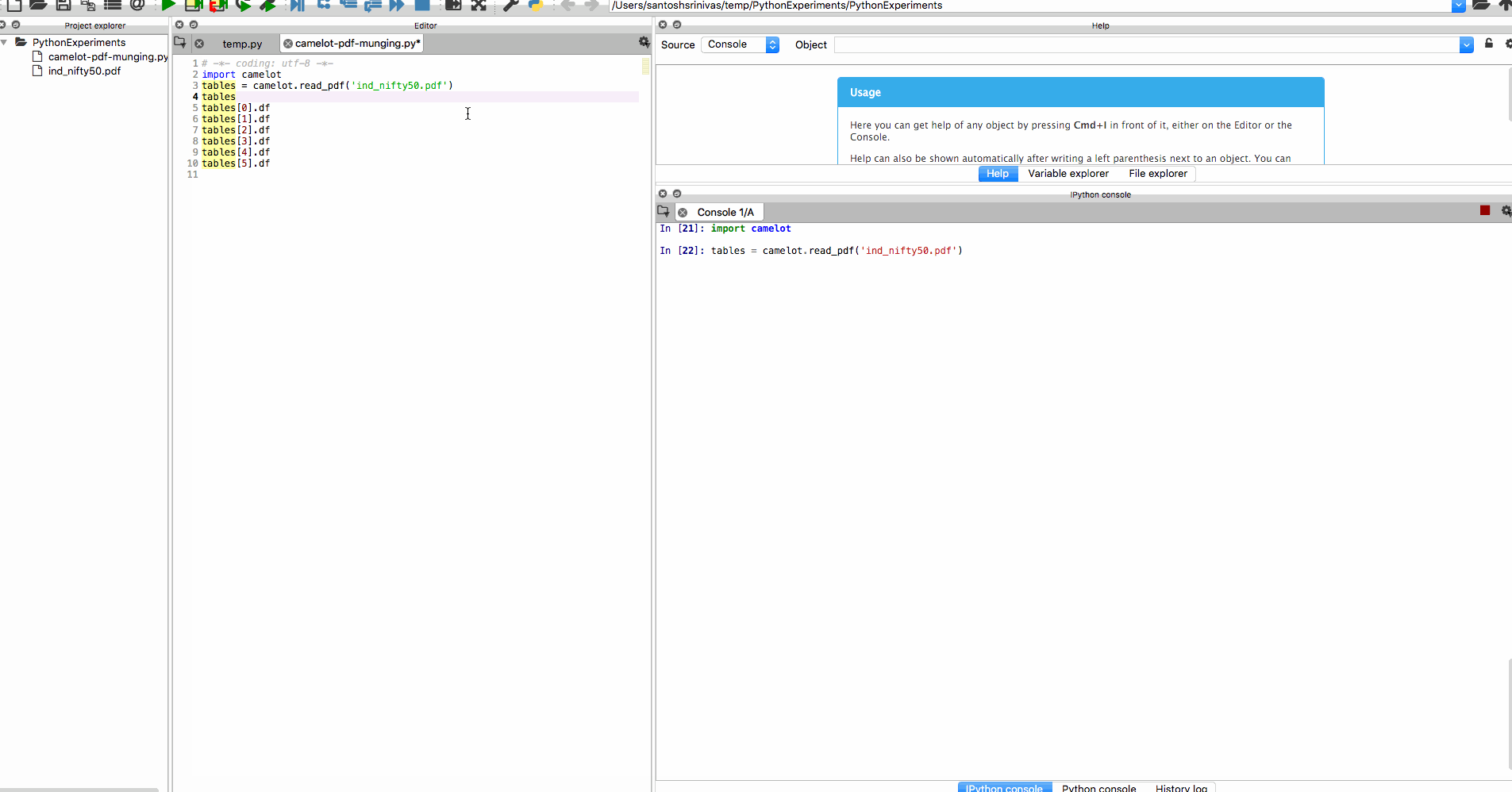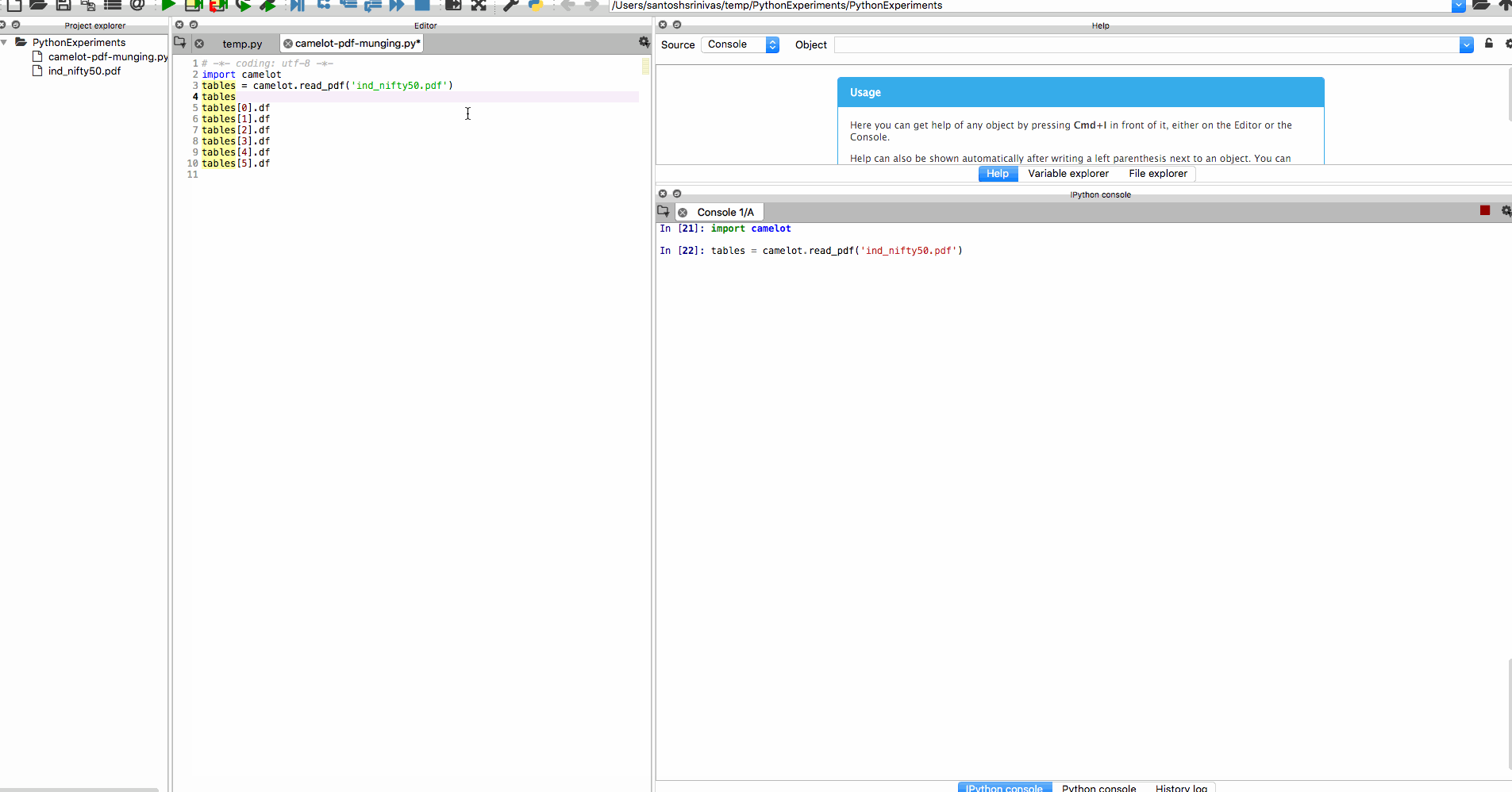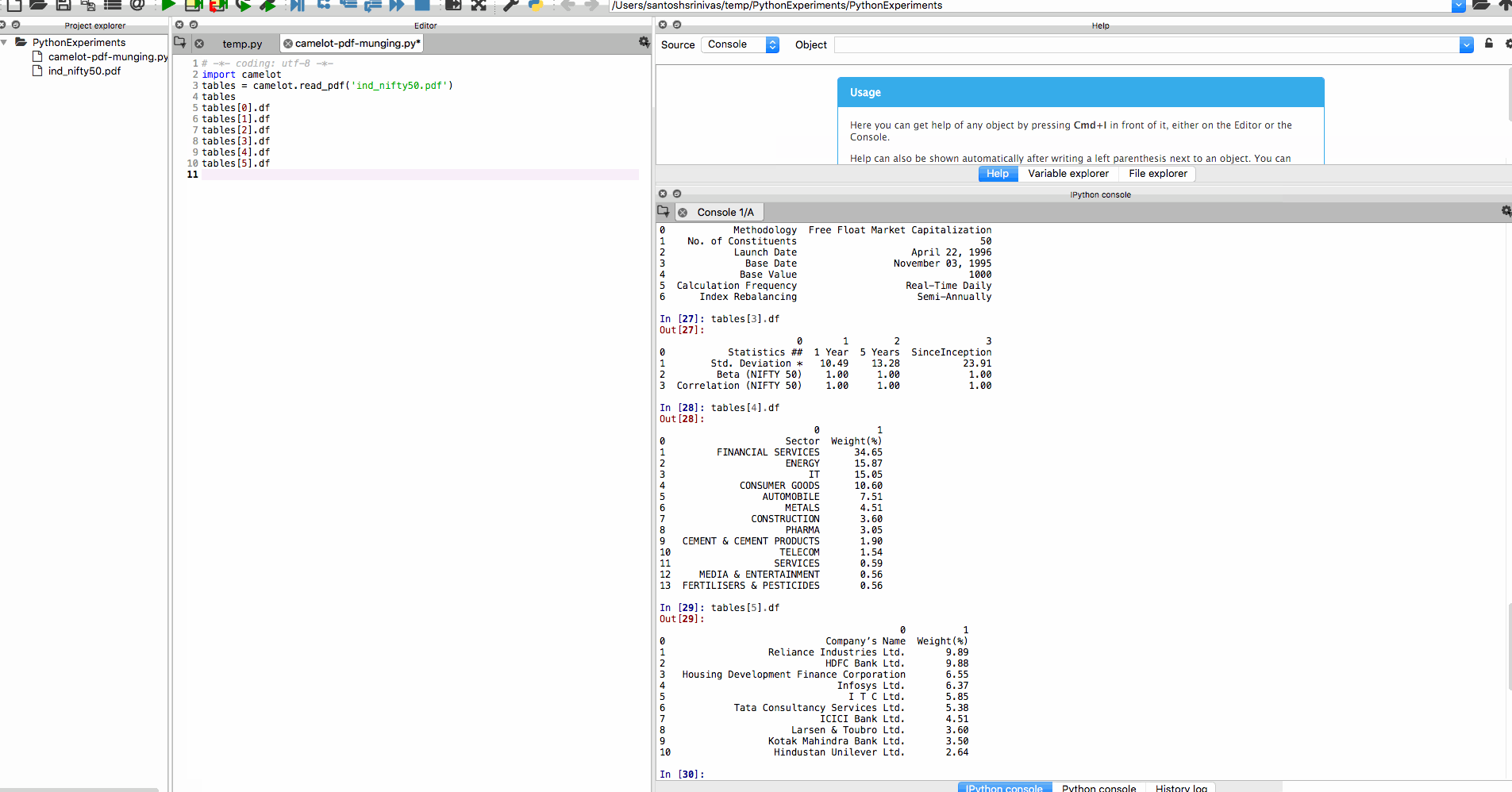
The file was imported and the tables imported pretty darn well! Cool stuff!
# -*- coding: utf-8 -*-
import camelot
tables = camelot.read_pdf('ind_nifty50.pdf')
tables
tables[0].df
tables[1].df
tables[2].df
tables[3].df
tables[4].df
tables[5].df
Lot of more advanced use cases available here. Looking good!