Puppeteer - API to control headless Chrome
I've used various options available for scraping in a headless mode including PhantomJS, Nightmare, ScraperJS, etc. Unfortunately, most of these options required xvfb which makes things slower, less reliable and utilizes a lot of memory.
Recently, Google launched Chrome that allows it to run in a true headless fashion. A few weeks later, Puppeteer which is:
a Node library which provides a high-level API to control headless Chrome over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome.
Couple of things to note:
Puppeteer requires at least Node v6.4.0, but the examples below use async/await which is only supported in Node v7.6.0 or greater
When you install Puppeteer, it downloads a recent version of Chromium (~71Mb Mac, ~90Mb Linux, ~110Mb Win) that is guaranteed to work with the API.
I like this because it explicitly install all dependencies and managing all code is much easier!
I had run into few issues (like always!) while running headless chrome on my Ubuntu 16.04 LTS instance mentioned here.
Luckily, everything worked after installing the following mentioned here
My simple code is as follows:
npm init
npm -S puppeteer
n use latest test.js
I use n for node version management. The simple scrape test.js is:
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch({headless: true});
const page = await browser.newPage();
await page.goto('https://google.com', {waitUntil: 'networkidle'});
// Type our query into the search bar
await page.type('puppeteer');
await page.click('input[type="submit"]');
// Wait for the results to show up
await page.waitForSelector('h3 a');
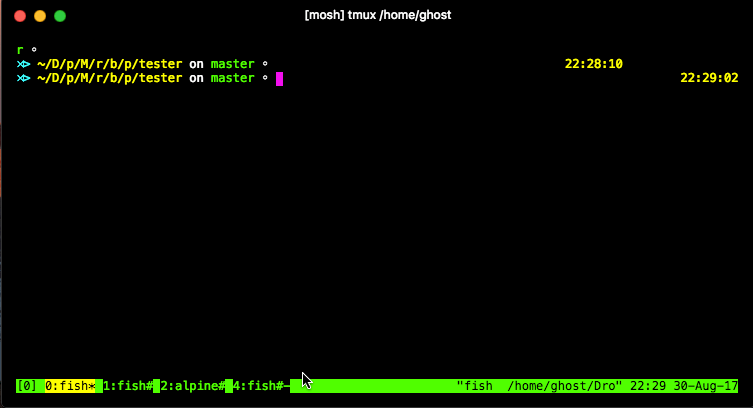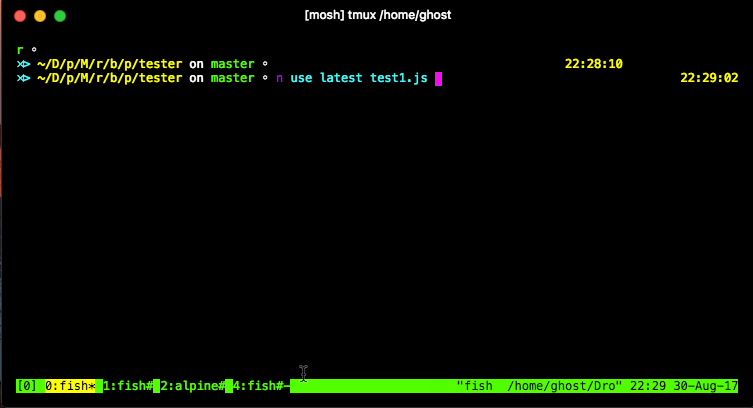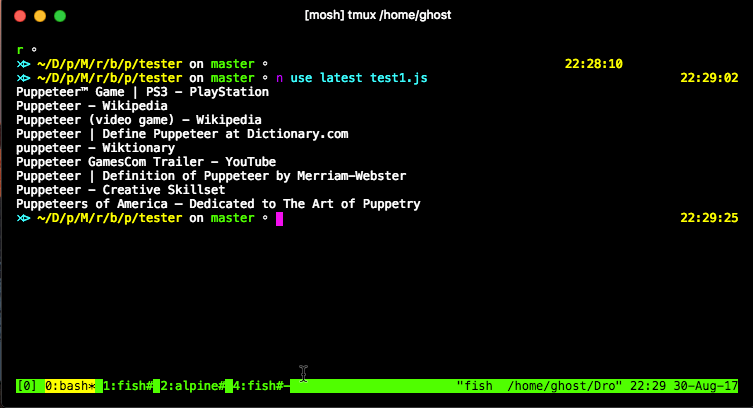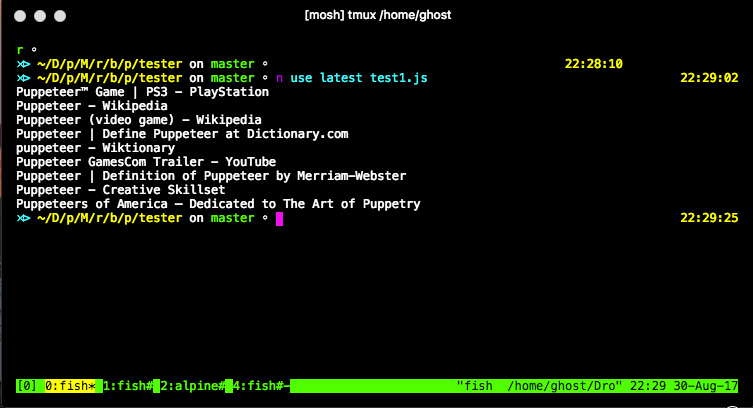
// Extract the results from the page
const links = await page.evaluate(() => {
const anchors = Array.from(document.querySelectorAll('h3 a'));
return anchors.map(anchor => anchor.textContent);
});
console.log(links.join('\n'));
browser.close();
})();
That's it! Awesome stuff!